드라마 W 대본을 활용한 데이터 분석 및 활용
※ 실제 구현 코드는 github상의 jupyter notebook을 참고하시기 바랍니다.
최근 데이터 분석 및 활용 기술의 발달로 데이터만 확보하면 다양한 것들을 해볼 수 있습니다.
기본적인 데이터분석 기법들로 웹상에 공개된 데이터를 가지고 놀아볼 방법을 찾던 중, 감사하게도 송재정 작가님께서 드라마 W의 대본을 공개 해 놓은것을 발견 하였습니다.(링크)
공개해 주신 대본은 실제 촬영에 활용된 대본으로 일정한 양식을 갖춰 작성되있어 활용 가능할 것으로 판단하여 이를 활용하기로 하였습니다.
이번 포스팅에서는 공개된 대본 한글파일을 데이터 분석에 활용 가능하도록 추출하는 내용을 담아보고자 합니다.
1. 처리방법 구상
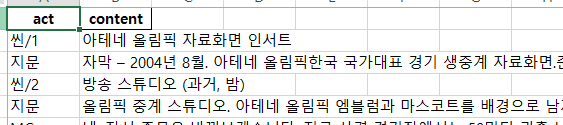
공개된 데이터는 한글파일로 되어 있는데, 데이터 분석을 위해서는 사용하는 언어에서 활용 가능한 형식으로 불러와야 하고, 데이터 분석을 위해서는 이를 요소들을 구분하여 데이터 테이블의 형태로 만들어야 합니다.
 |
 |
 |
2. 데이터 불러오기
(생략)
3. 데이터 탐험
데이터를 불러 왔으면 어떤 형태로 구성되어 있는지 확인 해야 합니다. 이를 통해서 데이터를 어떻게 원하는 요소별로 나누고, 개별 데이터들을 분리하여 나열할지 결정할 수 있습니다.
《표지》
['\ufeff서스펜스 멜로\n',
'\n',
'\n',
'\n',
'\n',
'\n',
'\n',
'W\n',
'더블유\n',
'\n',
'두개의 세계\n',
'\n',
'\n',
'\n',
'\t\t\t\t\t\t\t\t\t\t\t\t\n',
'\t\t\t\t\t\t\t\t\t\t\t\t\n',
'\n',
'\n',
'\n',
'제 1 회\n',
'\n',
'\n',
'\t\n',
'\t\t\t\t\t\t\t\n',
'\t\t\t\t\t\t\t\t극본 송 재 정\n',
'\n',
'\t\t\t\tW 등 장 인 물\n',
'\n',
'\n',
'1. 강철의 세상 ----------\n']《본문》
['\n',
'박교수\t여기 있네. (짜증나, 보던 핸드폰을 흔들며) 임마, 아버지가 딸 사랑하는 마음은 십분 이해하지만 말야, 만화 캐릭터를 이렇게 오연주라고 대놓고 해버리시면 나 같은 독자는 어떻게 보냐?\n',
'연주\t......\n',
'박교수\t이거 봐 명세병원 흉부외과, 아예 대놓고 내 딸입네 하시면 대체~ 너같은 돌팔이가 강철 목숨을 구하는 게 몰입이 되겠냐고 나한테? 그리고 뭐, 오연주가 미인이라고? 내가 그 대사 보고 순간 핸드폰을 집어던질 뻔 했어\n',
'연주\t(머리가 깨질듯) 교수님 나중에 얘기하시죠. 저도 이게 바라는 바가 아니구요..\n',
'박교수\t니가 아버지한테 압력행사 했지? 이름 넣어달라고? \n',
'\t이게 얻어오라는 스포는 안 얻어오고 명작에 오연주로 개칠을 하고 \n',
'연주\t(벌떡 일어나 박교수를 밀며) 저기 좀 나가주실래요? 제가 지금 교수님 말씀 들을 때가 아니라서요\n',
'박교수\t(황당) 어, 이게 나 밀었냐? 지금 날 밀어? \n',
'연주\t아 제발 좀!! 일단 나가시라구요!! (확 떠밀더니 문을 잠가버리는)\n']대사 분석에 불필요한 표지 부분을 제외하면 줄바꿈(\n), 탭(\t) 로 내용과 분류를 구분하고 있어 규칙성을 발견할 수 있습니다. 웹상에서 구할 수 있는 자료 중에는 가장 훌륭하게 규칙을 지키고 있는 자료라고 할 수 있습니다. 덕분에 약간의 코드로 내용과 분류들을 구분하고 데이터를 정제할 수 있습니다.
4. 데이터 정제
위에서 확인된 데이터의 패턴을 바탕으로 규칙성을 분석하여 데이터를 구분하고 적제할 수 있습니다. 아래는 실제 코딩을 수행 하기 전 구상한 의사코드 입니다. 실제로 코드를 작성하기 전에 작성되어 완벽한 로직은 아니지만 구현해야할 필수적인 사항들이 포함되어 있습니다.
《의사코드》
시작위치 = 0
for 요소 in 리스트:
정규 = 정규식컴파일("\t")
위치tab = 정규.찾기(요소)
구분 = 요소[:위치tab]
if 구분 == "씬/1":
break
시작위치 += 1
저장위치 = 0
for 요소 in 리스트[시작위치:]:
정규 = 정규식컴파일("t")
위치tab = 정규.찾기(요소)
if 위치tab:
구분 = 요소[:위치tab]
내용 = 요소[위치tab:]
if 구분:
구분저장[저장위치].추가(구분)
내용저장[저장위치].추가(내용)
저장위치 += 1
else:
내용저장[저장위치-1].추가(내용)
else:
저장위치 += 1위 구상을 바탕으로 실제 코드를 작성하여 대본을 테이블 형태로 만듭니다. 앞으로 수행해볼 데이터 분석에 활용할 기초자료가 됩니다.

5. 데이터 저장
공개된 16개의 대본을 위에서 작성한 코드에 돌려 테이블 형태로 만들고 이를 csv 등 저장 가능한 테이블 형태로 저장 합니다. 언제든 불러와 다양한 분석에 활용할 예정입니다.

마치며
이번 포스팅에서는 원본 데이터 확보 부터 이를 어떻게 할지 구상하고 이를 정제하여 저장하는 과정을 포스팅 해 보았습니다.
다음 포스팅에서는 확보한 데이터들을 활용하여 대본 내용들이 어떻게 구성되어 있는지 다양한 분석기법을 적용해 분석해 보도록 하겠습니다.
'Data-writing' 카테고리의 다른 글
| 데이터분석 전문가(ADP) 실기 후기 (3) | 2021.03.28 |
|---|---|
| 대본으로 놀아보기 #4 대본 요약하기(실패기) (1) | 2020.01.17 |
| 대본으로 놀아보기 #3 대본 감성분석, 연관분석, 토픽추출 (0) | 2020.01.11 |
| 대본으로 놀아보기 #2 대본 태깅 및 탐색적 자료분석 (0) | 2020.01.04 |
| 시대별 음악의 흐름 (0) | 2019.05.25 |